Transformers KV Caching Explained
How caching Key and Value states makes transformers faster
Caching the Key (K) and Value (V) states of generative transformers has been around for a while, but maybe you need to understand what it is exactly, and the great inference speedups that it provides.
The Key and Value states are used for calculating the scaled dot-product attention, as is seen in the image below.

KV caching occurs during multiple token generation steps and only happens in the decoder (i.e., in decoder-only models like GPT, or in the decoder part of encoder-decoder models like T5). Models like BERT are not generative and therefore do not have KV caching.
The decoder works in an auto-regressive fashion, as depicted in this GPT-2 text generation example.
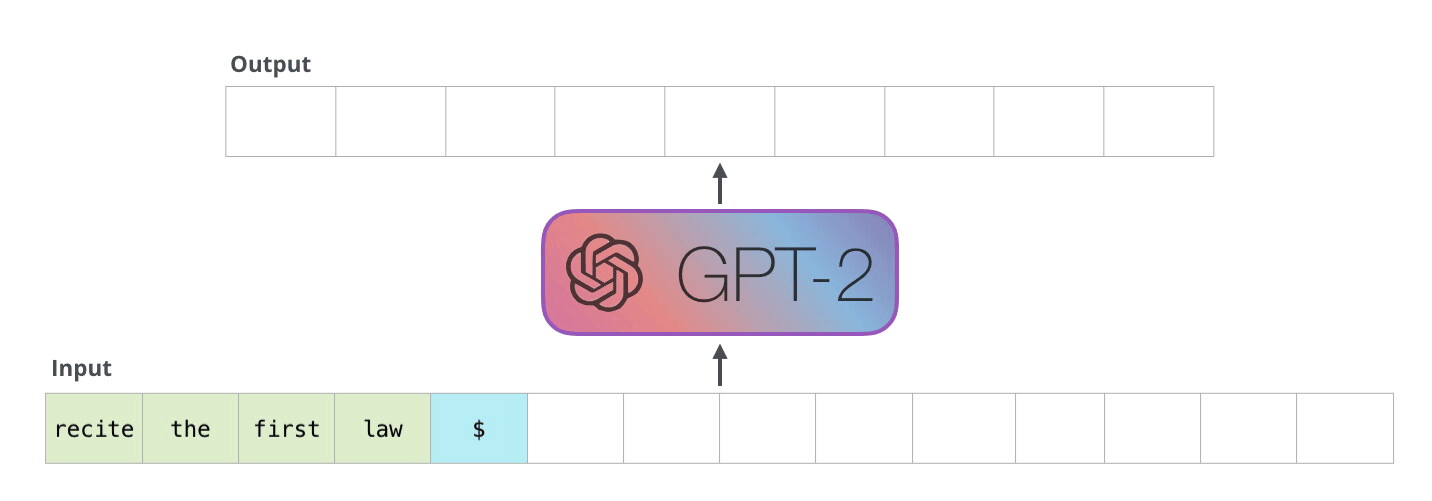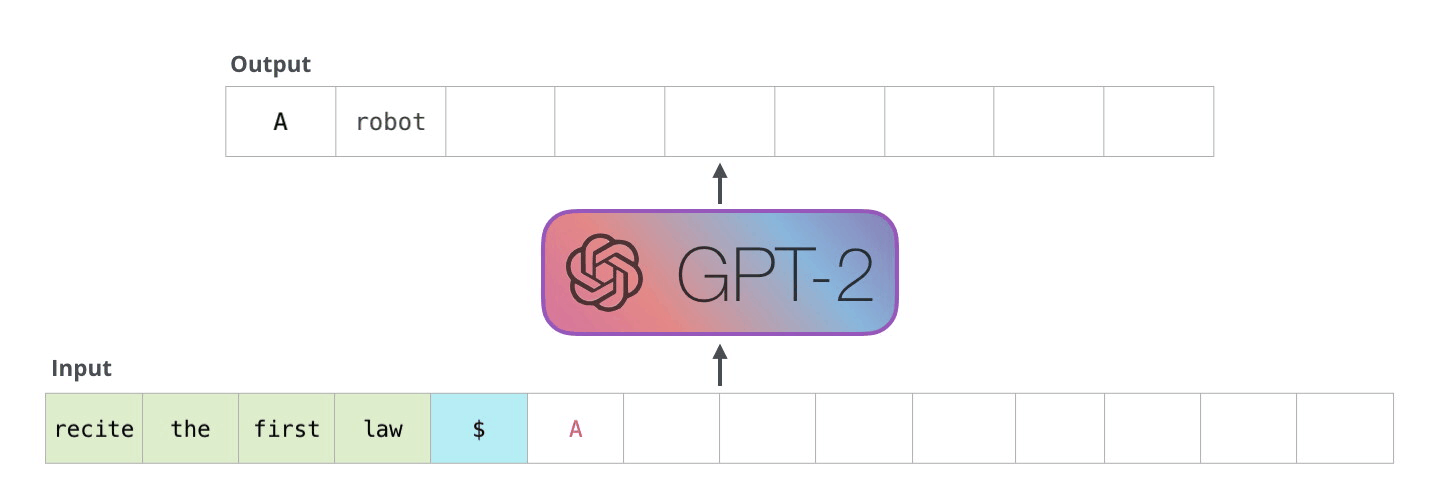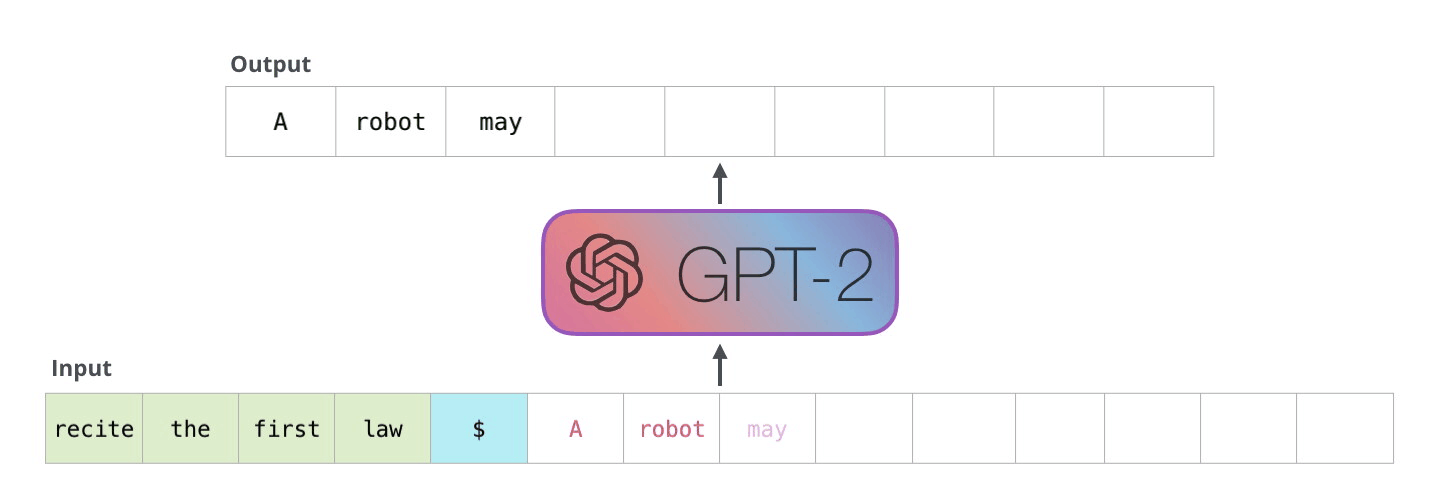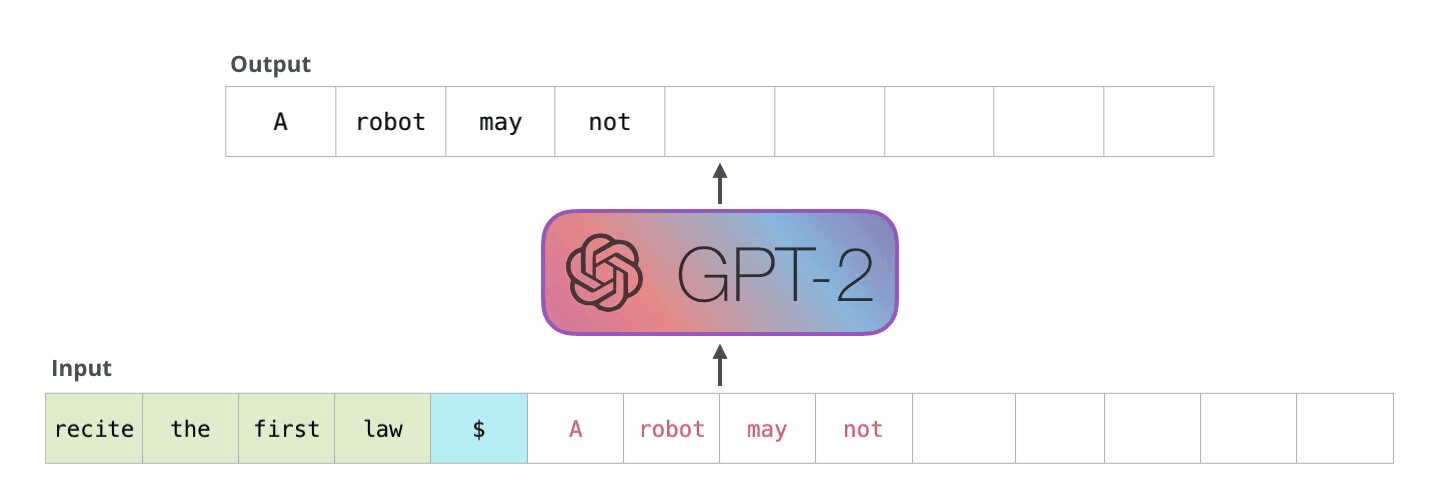
This auto-regressive behavior repeats some operations, and we can better understand this by zooming in on the masked scaled dot-product attention computation that is calculated in the decoder.
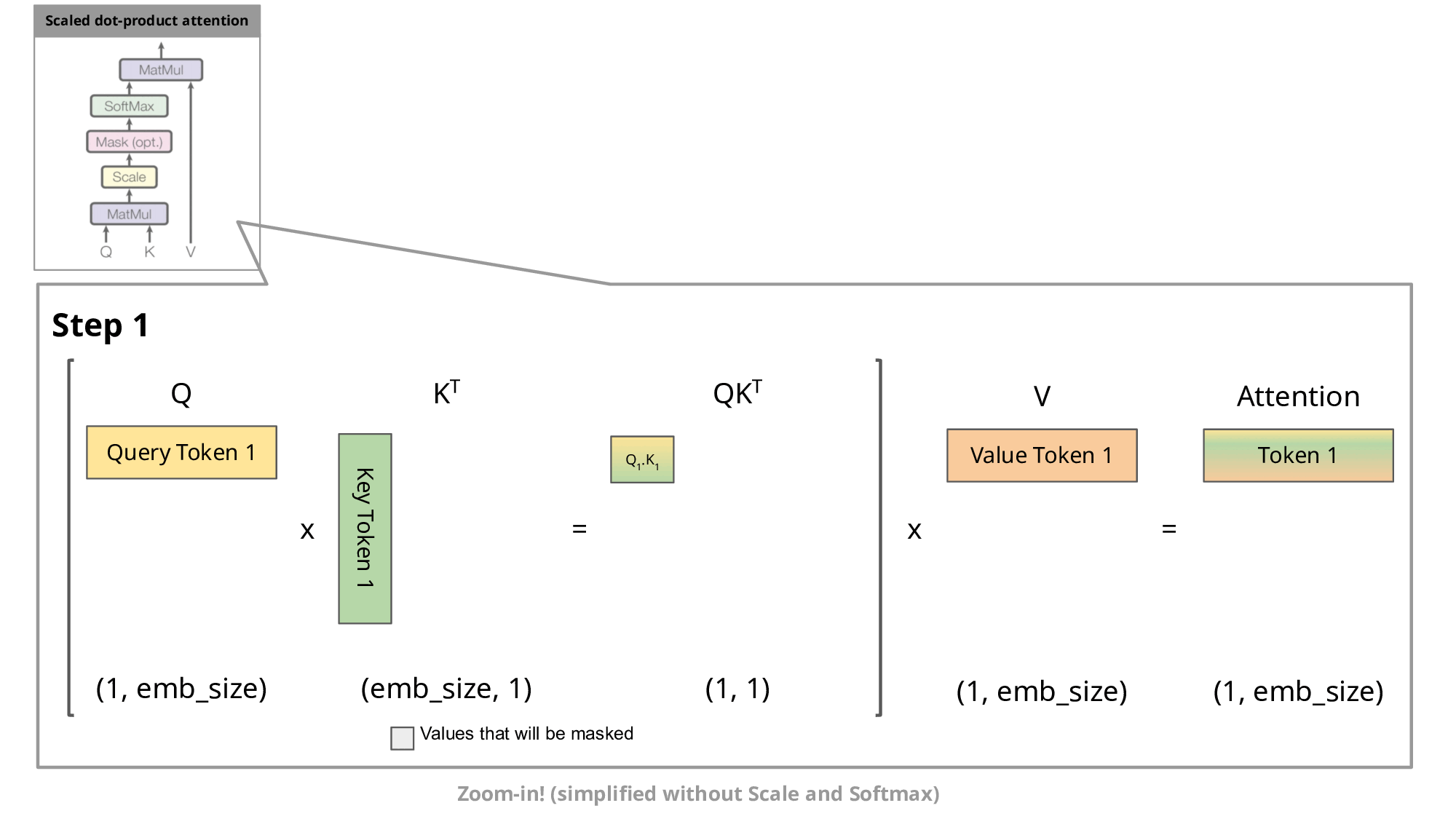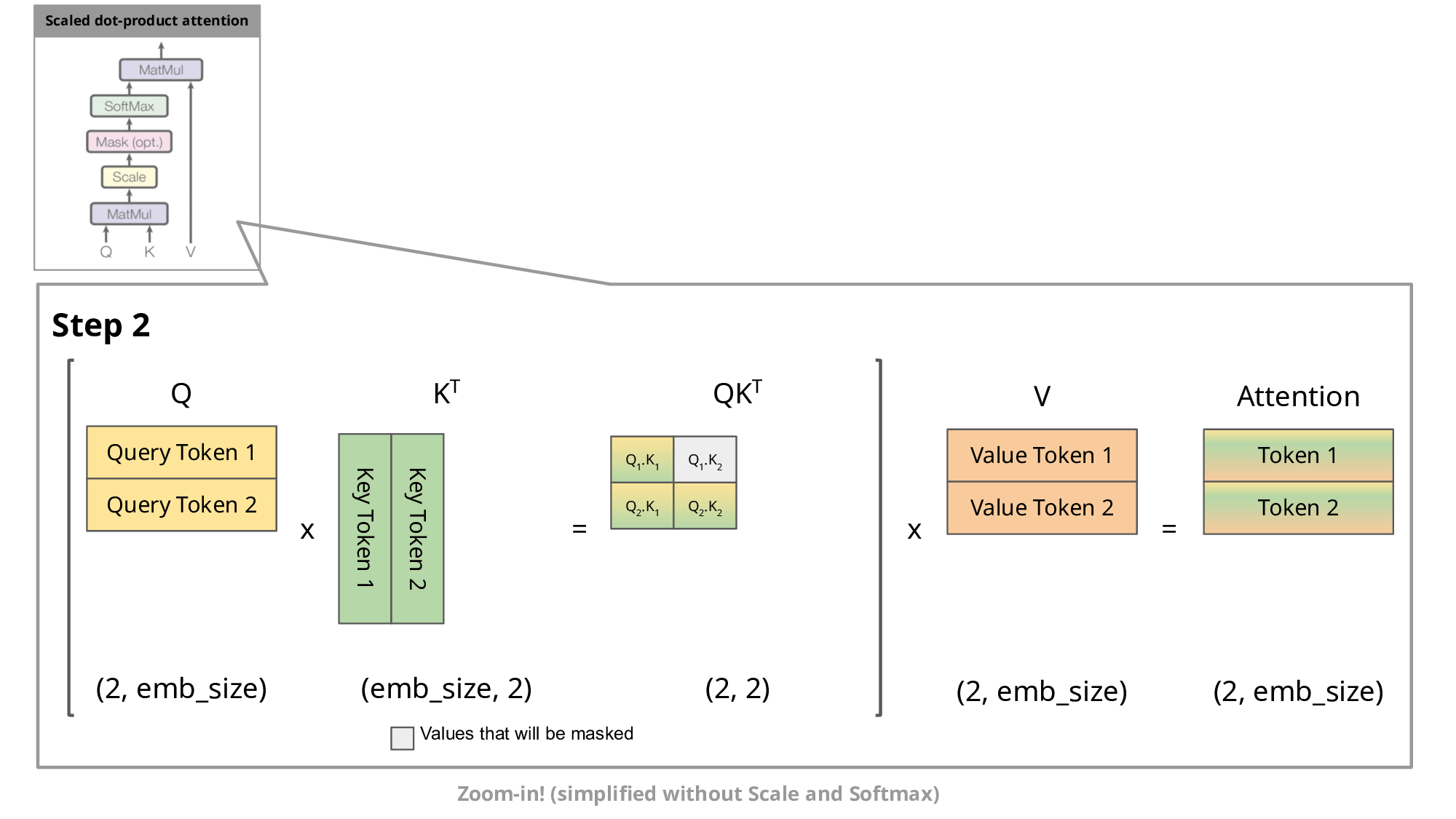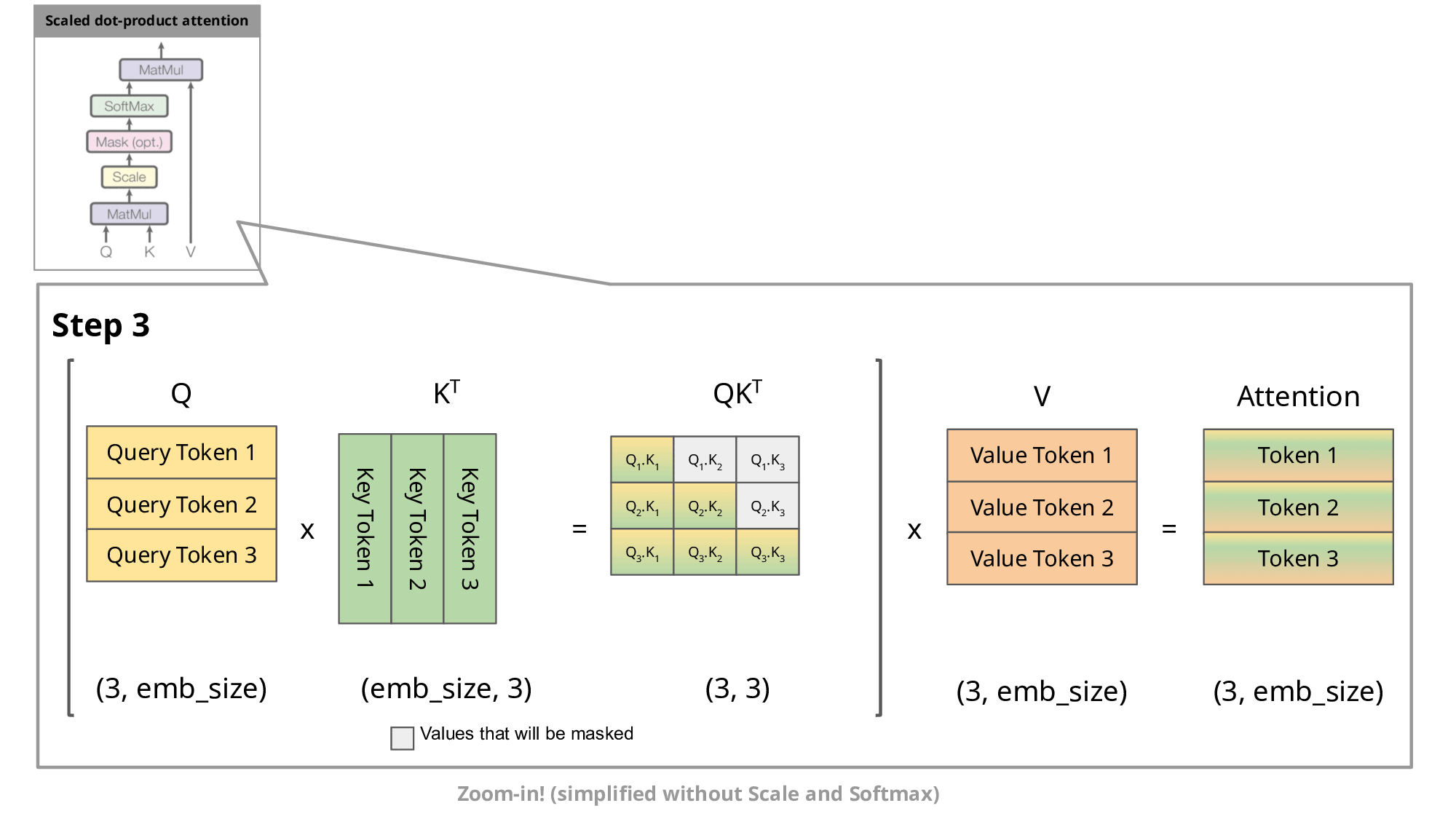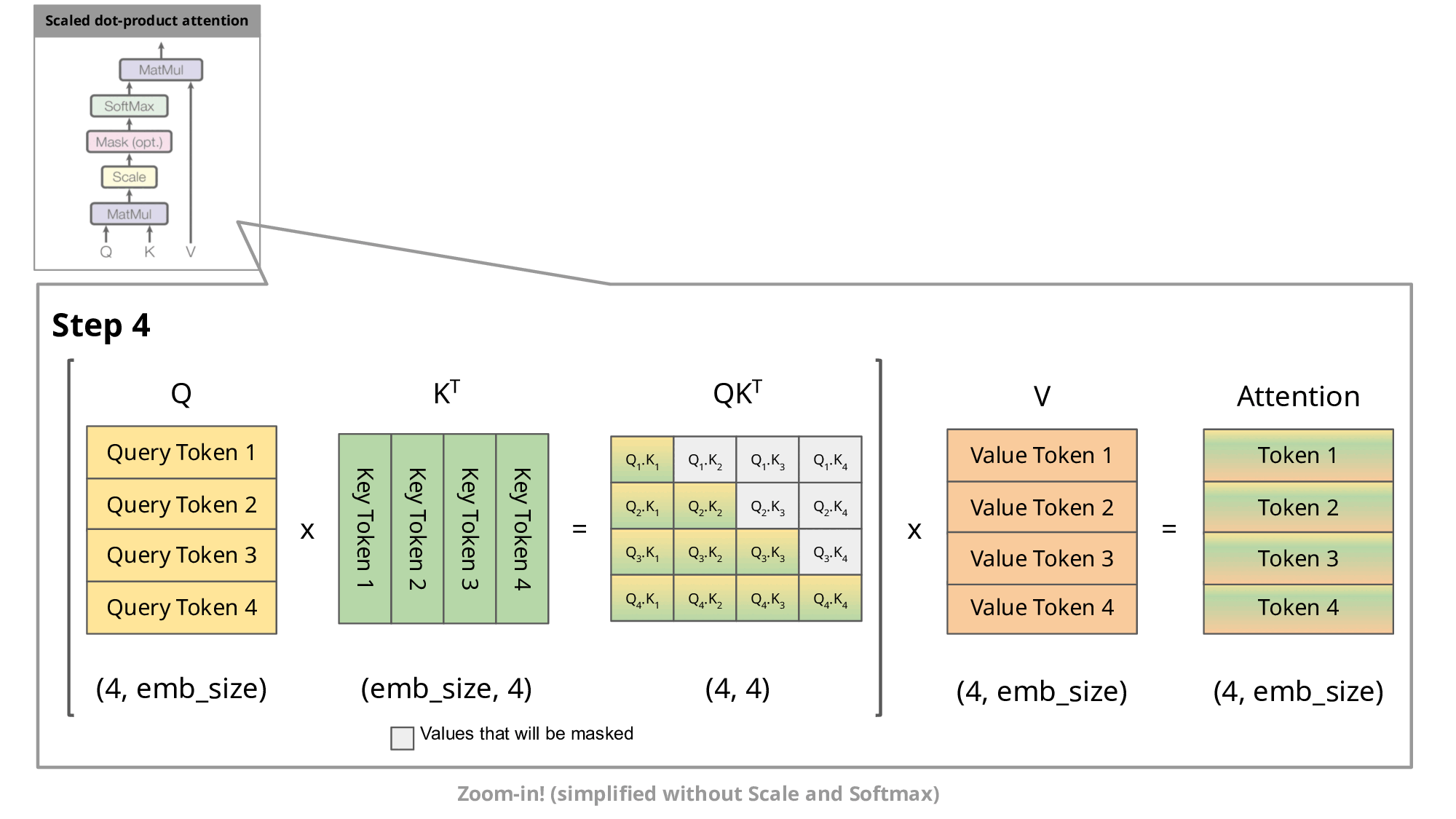
Since the decoder is causal (i.e., the attention of a token only depends on its preceding tokens), at each generation step we are recalculating the same previous token attention, when we actually just want to calculate the attention for the new token.
This is where KV comes into play. By caching the previous Keys and Values, we can focus on only calculating the attention for the new token.
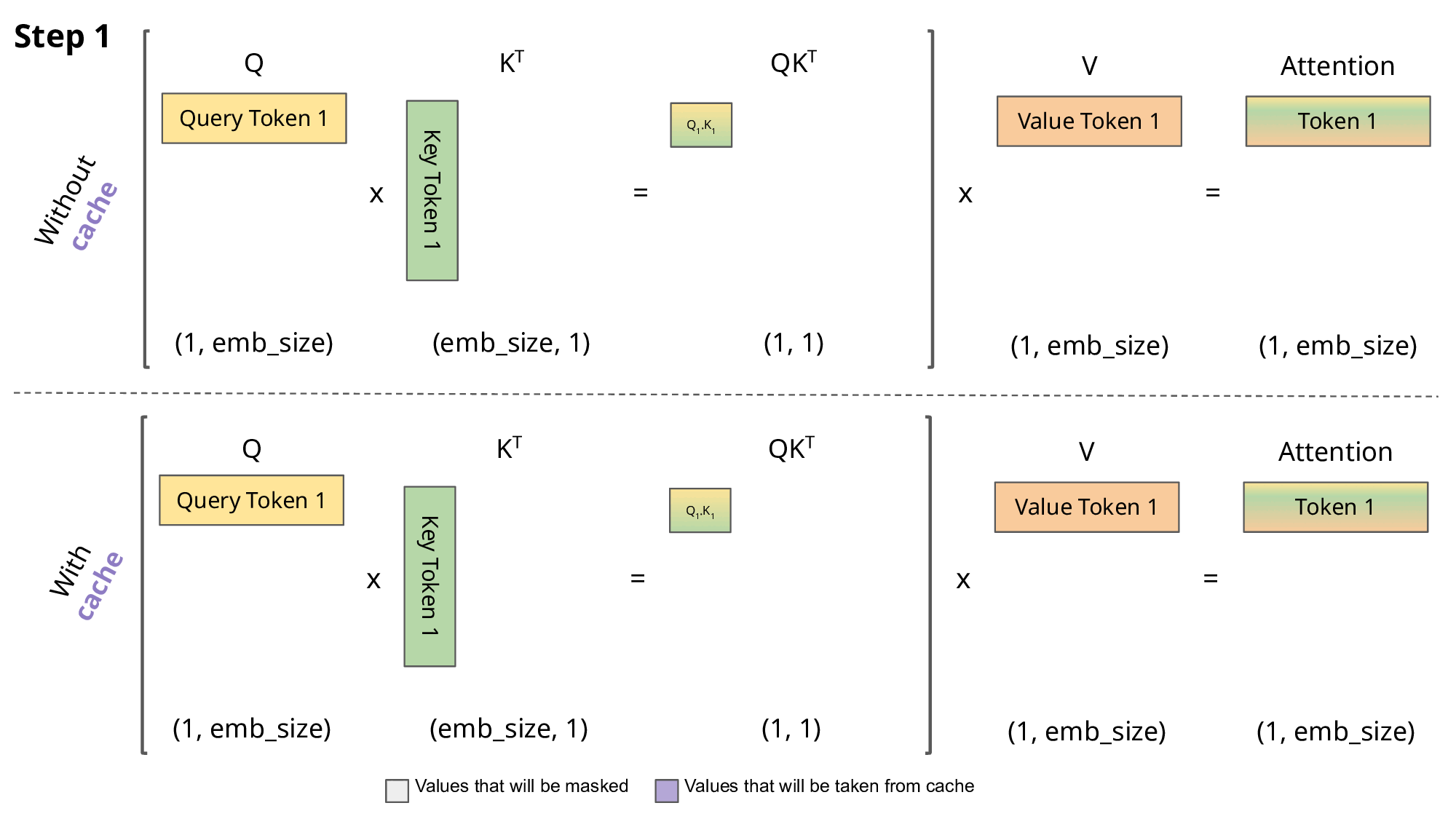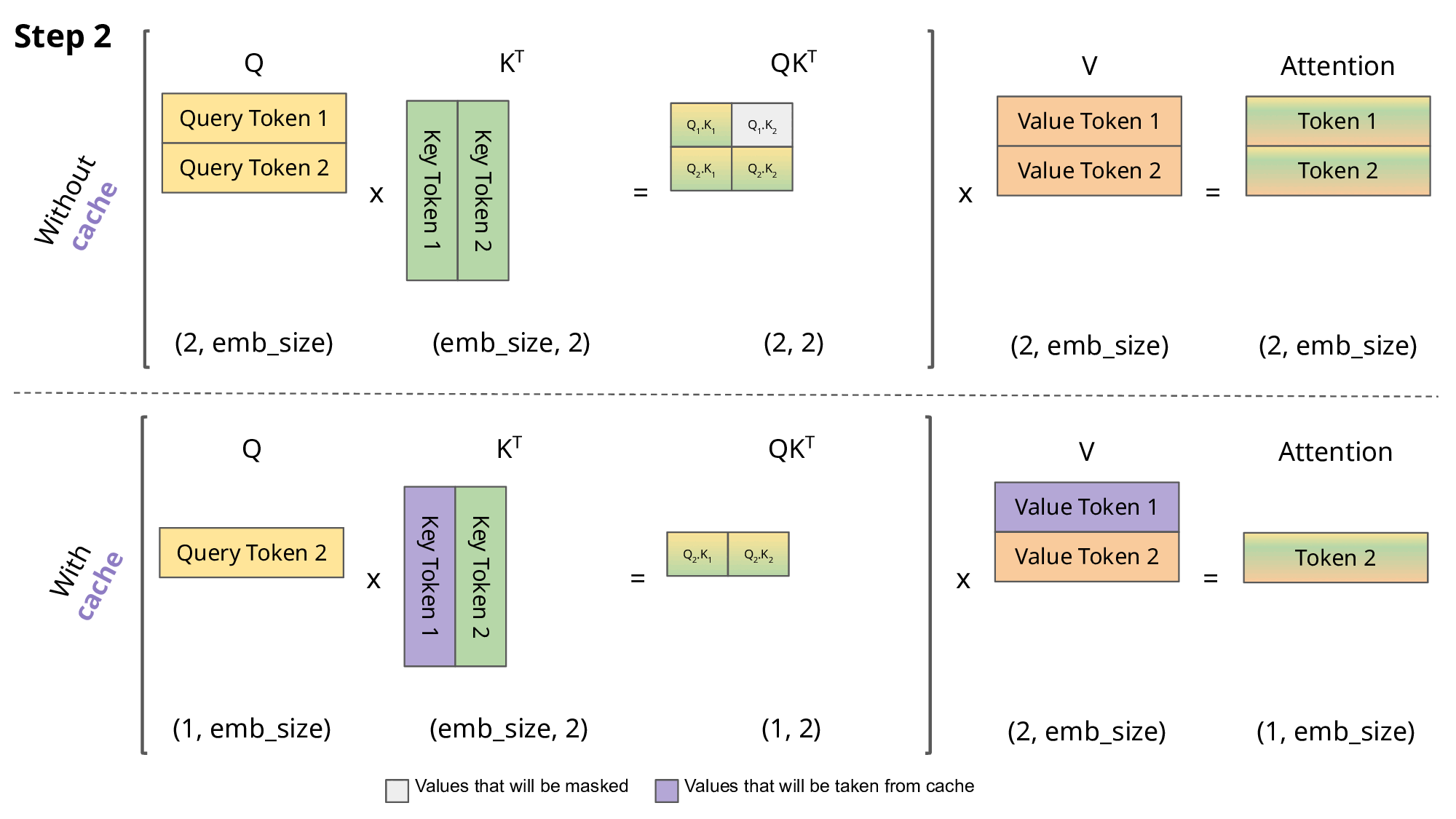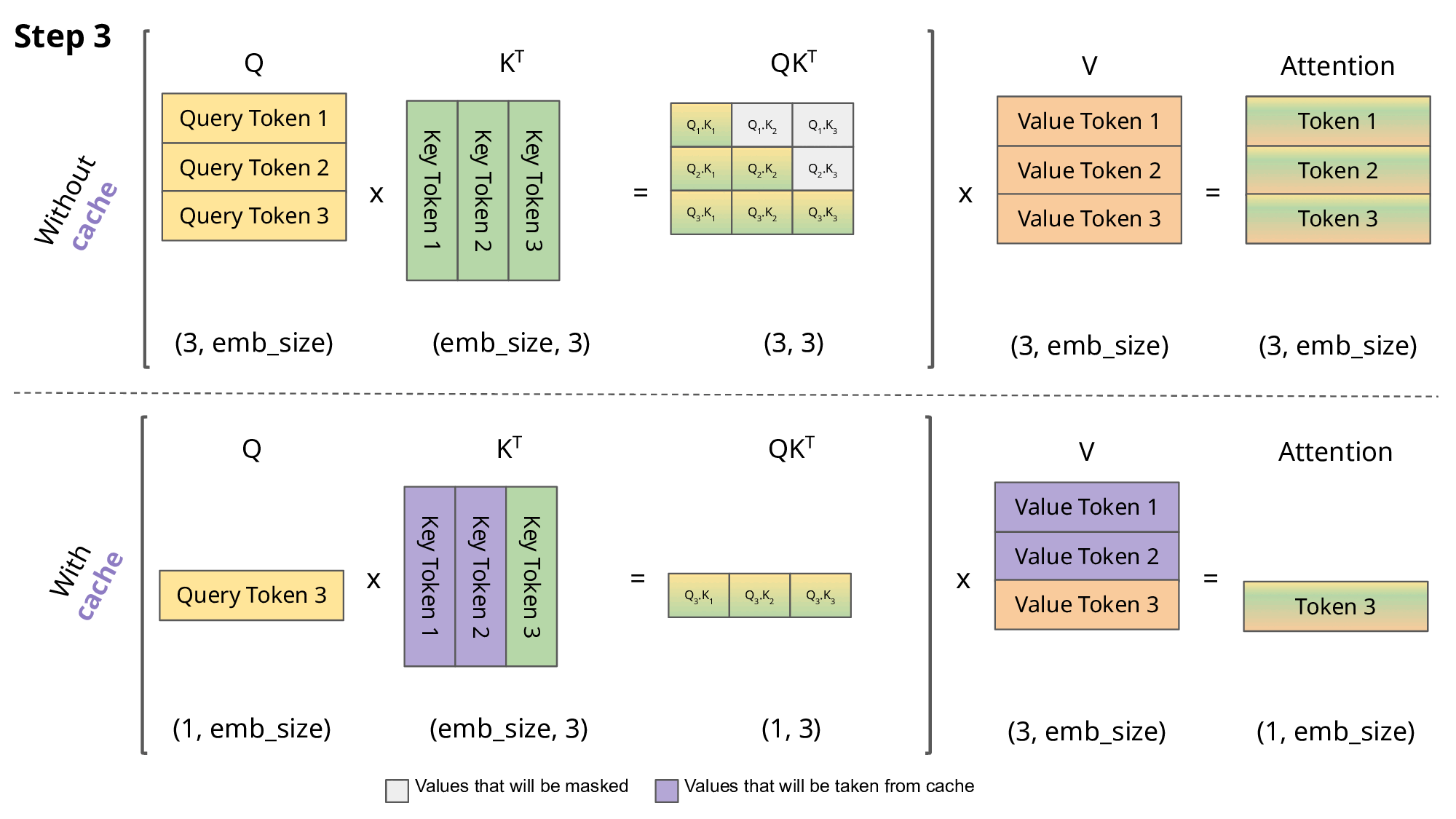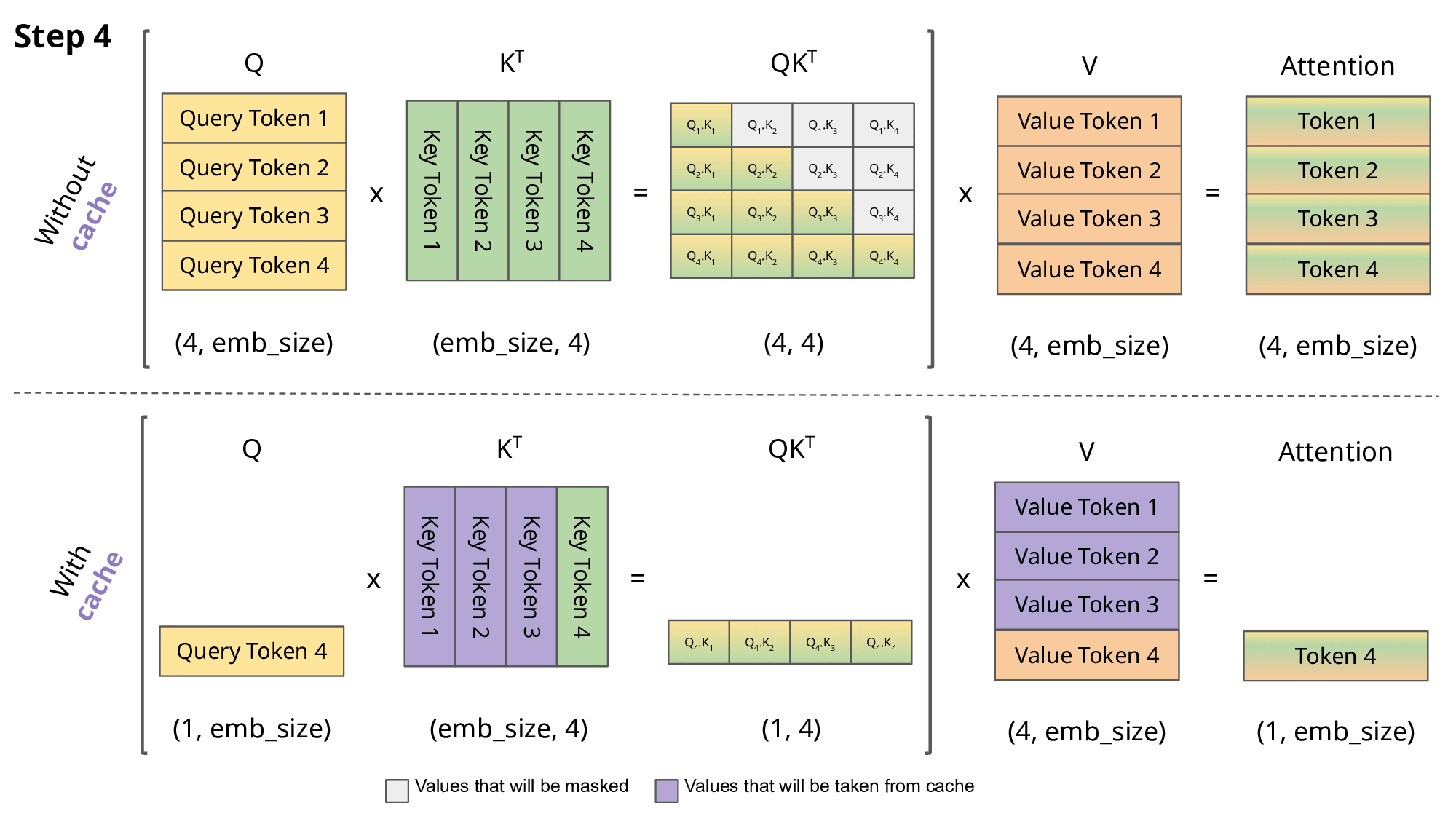
Why is this optimization important? As seen in the picture above, the matrices obtained with KV caching are way smaller, which leads to faster matrix multiplications. The only downside is that it needs more GPU VRAM (or CPU RAM if GPU is not being used) to cache the Key and Value states.
Let’s use transformers 🤗 to compare the generation speed of GPT-2 with and without KV caching.
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").to(device)
for use_cache in (True, False):
times = []
for _ in range(10): # measuring 10 generations
start = time.time()
model.generate(**tokenizer("What is KV caching?", return_tensors="pt").to(device), use_cache=use_cache, max_new_tokens=1000)
times.append(time.time() - start)
print(f"{'with' if use_cache else 'without'} KV caching: {round(np.mean(times), 3)} +- {round(np.std(times), 3)} seconds")On a Google Colab notebook, using a Tesla T4 GPU, these were the reported average and standard deviation times, for generating 1000 new tokens:
with KV caching: 11.885 +- 0.272 seconds
without KV caching: 56.197 +- 1.855 seconds
The difference in inference speed was huge while the GPU VRAM usage was neglectable, as reported here, so make sure to use KV caching in your transformer model!
Thankfully, this is the default behavior in transformers 🤗.
