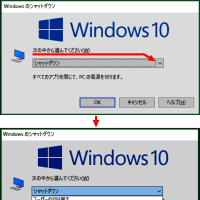
文字化けメールの解読に、メーラーで
「表示」⇒「エンコード」⇒「その他」⇒「Unicode(UTF-8)」
と選んだ「UTF-8」とは何でしょう。
「タブレットから送ったメールなら UTF-8 だよ」といきなり言われても、その記号をはじめて聞いた人は、何のことかさっぱりわかりません。
「Unicode(UTF-8)」でうまくいった、それだけでは字が読めるようになっても頭の中はすっきりしません。
頭のもやもやを洗い流すために、もうちょっと先まで首を突っ込んでみることにしました。
~~~~~~~~~~~~~~~~~~~~~~~~
~~~~~~~~~~~~~~~~~~~~~~~~
読めない文字はみな文字化けしているのでしょうか。
そんなことはありません。
世界にはものすごい数の文字の種類があります。
漢字、かな、カナ、英字などは、そのごく一部でしかありません。
知らない文字は読めないのが普通の人で、知らない文字を読んでしまうのは超人かお化けでしょう。

「世界の文字」 http://p.tl/TFbp
こんなサイトを偶然見つけました。
地球人が使っている、あるいはこれまでに使っていた、数ある文字の中で、コンピューターではどの文字を扱うことにしておいたほうがよいか、そして扱う文字それぞれに「0」と「1」の並べ方をどうするか、そういう符号化の仕方を決めておかなければ、情報通信は成り立ちません。
エンコードとは、読める文を送るために符号化することでした。
「UTF-8」はその様式の名前らしいのですが、人の名前と違って、方式名にはそれぞれいわれがあるはずです。
UTFは、Unicode Transformation Format 、ユニコードという名の変換形式です。
符号化のしかたを、大きな単一集合にまとめたのでユニコードと名づけたようです。
「-8」は、「0」と「1」の組み合わせを 8 桁ずつ使って符号単位にしている方式でした。
どういう文字の「0」と「1」の組み合わせをどう決めてあるのかは、何度聞いてもああそうぐらいにしか関心が湧きません。
データのやり取りの途中にもぐりこんで、いたずらを仕掛けてやろうという考えもないので、まったく用がないからです。
まずはこれで、少しだけ頭の霞が薄くなったように思います。